Looking back to the last years I spent with Power BI, many releases of Power BI Desktop made me dance (this means frantically tapping with one of my feet, as I’m not a dancer). And I know that many releases will make me tap again. Nevertheless, I consider this release, the December 2022 release, special. The reason for this is the introduction of the three new DAX functions. These functions are INDEX, OFFSET, and WINDOW.
What makes these functions special is simple, these functions allow us to compose powerful filter tables that have not been possible before or at least require very complex DAX code. These functions come with additional clauses, namely ORDERBY and PARTITIONBY. PARTITIONBY enables the partitioning of a virtual table. This partition is often called a window hence the name windowing functions. The clause ORDERBY enables the ordering of rows in each partition.
Note: For the first time since the introduction of DAX, we can order a virtual table, navigate this table with ease, and, even more importantly, use this ordered table as a filter modifier. Even writing this makes me dance again (you know – tapping).
Next to answering complex questions, what also makes these function special, is their elegance and simplicity. These functions allow a much broader audience to craft powerful DAX measures. Still, the understanding of specific concepts is required, but the hurdles are lower now.
This article is the first of a miniseries about these functions, starting with OFFSET. All the articles in this series use a single pbix. As the number of articles is growing, so will the pbix file. You can download the pbix file here
These new functions will help us to provide answers to questions that require traversing a sequence. This sequence can be determined by days (maybe the most obvious), by contract numbers, or, basically, by everything that can be ordered.
The previous value challenge
To get an easy start, I want to introduce you to a problem that I call the previous value. For simplicity I will use the following picture to explain the problem:
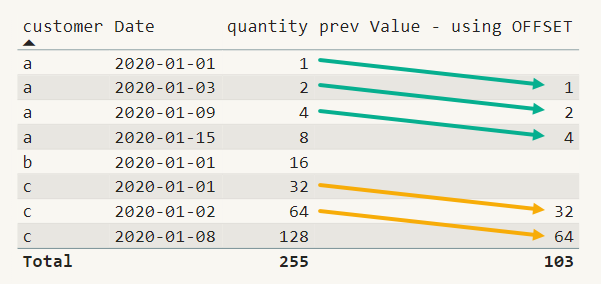
The challenge is to calculate the previous value “prev Value – using OFFSET” for a given row, e.g.,
customer:a | date:2020-01-15 the previous value is 4
For the row
customer:a | date:2020-01-09 the previous value is 2
But the previous value for
Customer:b | date:2020-01-08 is not 2 (customer:a, date:2020-01-03), instead, it’s 64 because the data has to be partitioned by customer.
Another challenge (next to partitioning) is the distance from the given (or current) row to the previous row. Navigating from the given row
customer:a | date:2020-01-15
to its predecessor, a distance of 6 has to be bridged, whereas the distance from the given row
customer:a | date:2020-01-09
to its predecessor is only 1.
For this reason, it’s not possible to use PREVIOUSDAY if the data type is date or datetime, and we are also not able to use
[something] – distance
as the value of distance can be variable. There is a more or less obvious approach to tackling this challenge. Unfortunately, this approach becomes terribly slow when the number of rows that must be traversed is growing. As this challenge is common to my colleagues, I came up with a not-so-obvious approach. My approach is very fast (but not trivial, not to say complex). I described this approach in this article some time ago: The previous value (before OFFSET)
Offset to the rescue
Here you will see the DAX statement that is tackling the previous value challenge gracefully:
prev Value - using OFFSET =
CALCULATE(
SUM( 'fact'[quantity] )
, OFFSET(
-1
,SUMMARIZE(
ALLSELECTED( 'fact' )
, 'customer'[customer]
, 'calendar'[Date]
)
, ORDERBY( [Date] )
, PARTITIONBY( [customer] )
)
)
Before I delve deeper into the above statement let’s have a look at the syntax of the OFFSET function: OFFSET syntax
OFFSET (
<delta>
[, <relation>]
[, <orderBy>]
[, <blanks>]
[, <partitionBy>]
)
With the given syntax it becomes obvious that the above statement is using all the parameters except the <blanks> parameter, the most simple one is
<delta>, this parameter determines the distance that has to be traveled from the current row
<relation>, a table expression that returns the output row
<orderBy>, the clause that determines how the table will be ordered (given that the table expression is used and finally
<partitionBy>, defines how the table will be partitioned.
If you compare the above statement leveraging the power of the new OFFSET function, with the code of the measure
“prev Value - fast maybe smart but not gracefully,”
I’m pretty sure you will
understand what I mean 😊
Nevertheless, looking at the above DAX code, it does not reveal it’s elegance and beauty immediately as the function OFFSET is using the “weird” function ALLSELECTED not to mention the new function clauses ORDERBY and PARTITIONBY.
Offset dissected
On the report page OFFSET - dissected you will see a single table visual only containing a single measure: OFFSET (ToJson). This measure contains only the OFFSET part used inside the measure “prev Value - using OFFSET”, the result of OFFSET is transformed into a scalar value by using the function TOJSON, introduced to our arsenal just a month ago.
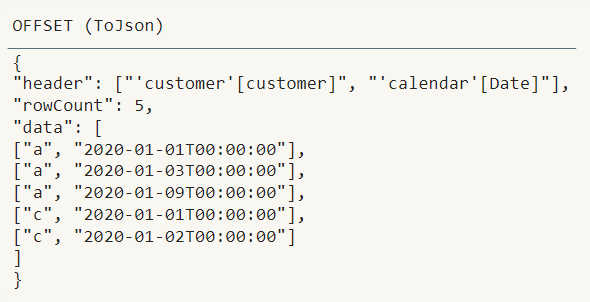
The result of the measure shows exactly the table content needed to filter the fact table to calculate the value 103 for the Total row.
In the next paragraphs, I will explain in more detail how this works, but first, a single sentence from the official documentation that reveals all the magic of OFFSET in 22 words.
“Returns a single row that is positioned either before or after the current row within the same table, by a given offset.”
To understand the magic of OFFSET I will start on the current row (customer:a | date:2020-01-03):

Calculating the previous value (prev Value) for the current row, marked by the blue triangle requires two steps.
These steps are:
1. Removing the current filter applied by the Date column but keeping the filter applied by the customer column.
2. Navigating to the previous row to extract its value
The first parameter of the OFFSET function will be -1; this allows navigating to the previous row, this appear obvious from the given task.
As always it boils down to composing the table expression or, as it is called in the documentation – the relation.
When composing the table expression, we have to keep in mind that ALL( ‘calendar’ ) can not be used as this will return all dates, also 2020-01-02. But that date is not part of the current filter context. ALLSELECTED( ‘calendar’[date] ) is also not sufficient as this will also contain the 2nd of January, coming from customer c.
For this reason, using ALLSELECTED( ‘fact’ ) is a good start. The measure
ALLSELECTED - fact (ToJson) is visualizing the result. Obviously it contains way much too many rows and columns. To calculate the previous value the columns customer and date are sufficient. For this reason SUMMARIZE is used to restrict the result to the needed columns and remove duplicates. The result is visualized by the measure.
The result still has too many rows,

but this can be narrowed down by wrapping the summarize into a CALCULATETABLE and using VALUES( ‘customer’[customer] ) as a filter table, the measure
ALLSELECTED - fact CALCULATETABLE
is exactly doing this:

Now we retrieve all the available rows for customer a, but still, we have to navigate to the previous row, this is very difficult as we have to know what is the current row and what is the previous row.
For this reason, I will now use OFFSET in different variations until the final filter table is returned.
The measure
OFFSET - PARTITIONBY delta 0
is the first iteration (be aware that this measure is using 0 as the first parameter). For this reason it returns all the available rows of customer a. If the first parameter is changed from 0 to
-1 only the rows are returned that have a previous value. If the ‘calendar’[date] column is added to the table visual we see the exact row that has to be used as a filter table to calculate the
previous value:

Now, it’s time to have a closer look at the measure prev Value - using OFFSET
CALCULATE(
SUM( 'fact'[quantity] )
, OFFSET(
-1
,SUMMARIZE(
ALLSELECTED( 'fact' )
, 'customer'[customer]
, 'calendar'[Date]
)
, ORDERBY( [Date] )
, partitionBY( [customer] )
)
)
again, to fully understand what’s going on.
The first parameter, the numeric expression, is calculated with the new filter context applied, but the filter table generated by OFFSET is calculated considering the old filter context. This old filter context is considered by the clauses ORDERBY and PARTITIONBY. I recommend reading this article to get a refresher on the intricate workings of CALCULATE: The logic behind the the Magic of DAX Cross Table Filtering
I have tested OFFSET to get the previous value and I’m amazed by its performance and its simplicity. In the articles of this series I will cover some simple algorithms like moving averages but also more advanced ones like detecting islands and gaps in a sequence.
From my early experience I think that ALLSELECTED will play a mature role in composing the relationship the filter table.
The great minds from SQL BI have a great article explaining ALLSELECTED: The definitive guide to ALLSELECTED
I’m wondering if you, my dear reader, consider an additional article that explains ALLSELECTED differently helpful (maybe not as complete, but simpler). If so, please leave a comment here or on twitter answering to this tweet:
Additional resources
I assume that these functions will fuel many blog articles as they open the window to new analytical capabilities, here are two articles that I’m currently aware of:
-
Get the change from cumulated values by Štěpán Rešl (OFFSET and its usage with Calculation Groups | LinkedIn)
Here Štěpán describes how OFFSET helps to calculate the change from cumulated values and combines this with a CALCULATION group. - An introduction to OFFSET by Marc Lelijveld (How OFFSET in DAX will make your life easier – Data –
Marc (data-marc.com))
Here Marc provides a brief introduction to OFFSET.
Thank you for reading!
Kommentar schreiben
Oxenskiold (Mittwoch, 21 Dezember 2022 09:23)
Hi Tom, thanks for the article on OFFSET. It's a excellent write-up. Looking forward to yhe next articles.
PS: I would love to read your take on ALLSELECTED, especially if it takes another approach than the article from SQLBI. (the best of two worlds you know)
Raul (Samstag, 18 März 2023 05:24)
Exdelente articulo. gracia
Nick (Sonntag, 28 April 2024 19:48)
Thank you for this great article. It’s really hard to find info on how offset works.
Tom Martens (Sonntag, 28 April 2024 22:38)
I'm really happy you find this article useful!
Felix Meyer (Mittwoch, 02 Oktober 2024 11:28)
Your site visitors, especially me appreciate the time and effort you have spent to put this information together. Here is my website <a href="http://ps-chevilly.org/spip.php?action=cookie&url=http://webemail24.com/your-guide-to-email-marketing">Webemail24</a> for something more enlightening posts about Price Comparison Sites.