This article is a two-part article. The first part briefly introduces the world of JSON and why I consider reading and writing simple JSON documents a valuable asset. The second part is about extracting data from some of Power BI’s REST APIs. I will fill in the second part later.
why JSON?
JSON is a straightforward, text-based data-interchange format fully independent of any programming language. This simplicity is why JSON documents have become so widespread.
Often the result of querying a REST API is returned as a JSON document, but this is not the only use case why I consider it important to get familiar with reading from and writing to a JSON file. I think a JSON document is ideal for ingesting values into a Python script or any code, values that are helpful to control the logic and behavior of the script. But of course, it’s also easy to store the value of a variable inside the JSON document, where this value will be used when the script is running again.
Understanding JSON
Before we can use JSON in our developing projects, I think it’s necessary to understand the structure of a JSON document or JSON object. Most of the time, I use the terms JSON object and JSON document interchangeably. I think of a document when I read data from a JSON file (stored with the suffix JSON) or the result of a request against a REST API endpoint. I think of a JSON object when I think about the document's structure while reading or writing from or to the document.
The form/structure of a JSON document
A primitive JSON document looks like this:
{ data }
Curly braces { data } define an object, this object is represented by a collection of name/value pairs, multiple name/value pairs are separated by a comma. The next code block shows a very simple JSON document storing information about a single person:
{
"firstname": "Thomas",
"lastname": "Martens",
"nickname": "Tom",
"age": 55
}
If the JSON document contains information about multiple persons square brackets are used to combine multiple objects:
[
{
object 1
}
,{
object 2
}
]
Objects inside an array are separated by commas. The next code block shows a JSON document containing information about two persons:
[
{
"firstname": "Thomas",
"lastname": "Martens",
"nickname": "Tom",
"age": 55
}
,{
"firstname": "Cordula",
"lastname": "not Martens",
"eyes": "blue-grey-green"
}
]
According to the JSON specification (https://datatracker.ietf.org/doc/html/rfc7159.html#page-1) square brackets are defining an array.
Reading from and writing to a simple JSON file
Whenever I develop a program, it’s not intended to run continuously; instead, it runs and stops when done. Next, I design my programs so they can be started more than once. Nevertheless, I often want my programs to behave differently when running a 2nd time or even a 3rd time. If you are familiar with Azure Functions Apps, then you also know that you can define variables outside of the functions that help to control the behavior of the functions.
But I’ve been focusing on Python scripts for quite some time, running from inside a notebook tied to a Microsoft Fabric lake house. This setup does not provide variables that help me to direct my Python scripts, but fortunately, a notebook can utilize resources stored inside a folder called “Build-in.” Here you will find more information about the build-in folder that provides a Unix file system to each notebook: https://learn.microsoft.com/en-us/fabric/data-engineering/how-to-use-notebook
When working with REST APIs as a data source, we get used to throttling when we hit the REST endpoint too often, limits regarding the number of objects inside a JSON “answer”, or overall performance issues compared to database queries. For this reason, we have to prepare our Python scripts to meet the above-mentioned challenges and more. Often a REST API endpoint provides a result that contains fields like “createdDate” or “last modified date”, e.g., the Power BI REST API:
GET https://api.powerbi.com/v1.0/myorg/admin/datasets
returns a JSON document that contains a field called “createdDate.”
This field contains the datetime value when the semantic model was created. Assuming there are a lot of semantic models in your tenant, your script becomes more efficient if you are only asking for the datasets that have been created after a given date. The next code snippet shows how the request will look using the Python package requests, when the endpoint is asked for semantic models created after a given datetime:
requests.get("https://api.powerbi.com/v1.0/myorg/admin/datasets?$filter=createdDate%20gt%202018-02-22T06:54:36.957Z", headers = header)
The date and time used in the above request is the
22nd of February, 2018 at 06:54:36.957 AM (UTC).
Writing the maximum createdDate value from the current script execution to the JSON file will make the execution of a subsequent execution more efficient, when the stored datetime value is considered. If you are wondering about the format of the datetime value it’s because of the fact that Power BI REST APIs are adhering to the filter specification of oDATA 4, here you will find this specification: https://docs.oasis-open.org/odata/odata/v4.01/cs01/part2-url-conventions/odata-v4.01-cs01-part2-url-conventions.html#sec_SystemQueryOptionfilter
The next sections are about reading from a simple JSON file and even more important writing to the JSON file.
Reading from a simple JSON file
Please be aware this is only about reading from a JSON file to control the execution of the Python script. The below example is about reading a value from a JSON file and do things differently depending on that value. Please, consider this not a best practice for incrementally loading data from a source (this will be covered in a future article).
Assuming the JSON theHiveDatasets.JSON is stored in the resource folder and looks like this
{
"readEverything": "true",
"LastCreatedData": "none"
}
The below code snippet shows how to open and read a simple JSON document from within a notebook that is executed inside a Fabric workspace, the last line stores the value from the name “readEverything” to the variable “readAllDatasets”:
#thePath = f"{mssparkutils.nbResPath}"
# /synfs/nb_resource
# the complete path of f: /synfs/nb_resource/builtin/theHiveDatasets.JSON
#f = open(f"{mssparkutils.nbResPath}/builtin/theHiveDatasets.JSON", buffering = -1)
f = open("./builtin/theHiveDatasets.JSON", buffering = -1)
json_file_content = json.load(f)
#print(type(json_file_content))
display(json_file_content)
# print the content of the element 'LastCreatedDate' of the dict
print(json_file_content['LastCreatedDate'])
#storing a value from the JSON to a variable:
readAllDatasets = json_file_content['readEverything']
Be aware that reading from a JSON file stored in the resource folder of the notebook can be achieved by many ways, some are inside the above snippet but are commented. My favorite method reading “simple” JSONs is using plain Python in combination with the json package. I also tend to use the relative path method because it’s compatible with developing with Visual Studio Code:
f = open("./builtin/theHiveDatasets.JSON", buffering = -1)
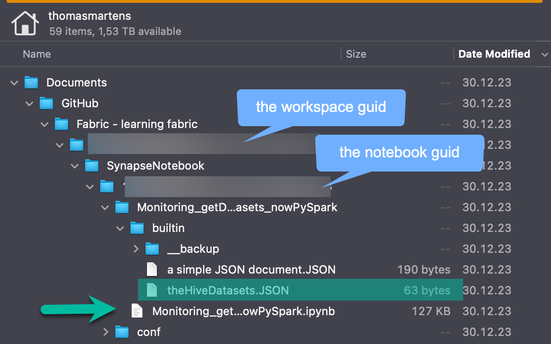
The next image shows the folder structure on my local machine:
Update a JSON document and save the change
Assuming there is a Spark dataframe called df_datasets, that contains the result of the following Power BI REST API request:
requests.get("https://api.powerbi.com/v1.0/myorg/admin/datasets?$filter=createdDate%20gt%202015-12-22T06:54:36.957Z", headers = header)
Without any transformations the dataframe will contain a column called “createdDate”, then you can extract the max value of the that column with the following snippet, inspect the type, and print the value:
from pyspark.sql.functions import max as max_
datasets_maxCreatedDate = df_datasets.agg(max_("createdDate")).collect()[0]['max(createdDate)']
print(type(datasets_maxCreatedDate))
print(datasets_maxCreatedDate)
If you are wondering why I imported the PySparl max function as max_, the reason is simple. The Python function max does not work with columns.
- .collect(), transforms the dataframe into a list,
- .collect()[0], fetches the first value of the list (of course, there only is one)
- .collect()[0][’max(createdDate)’], finally fetches the column from the first value of the list,
these transforms return a simple string that then can be used to update the JSON document. More transformations are explained in the the 2nd part of this article.
The following snippet updates and writes the JSON document to the “file system”:
# updating the JSON document
json_file_content['LastCreatedDate'] = datasets_maxCreatedDate
# writing the JSON document to the "file system"
with open("./builtin/theHiveDatasets.JSON", 'w', encoding='utf-8') as f:
json.dump(json_file_content, f, ensure_ascii=False, indent=4)
Reading and writing simple JSON documents make my Python-based Fabric notebooks more efficient and more simple.
Thank you for reading!
Kommentar schreiben